The AI harness had already fixed it
Before I woke up and asked about the beta restarts, Codex + Quave ONE MCP had already investigated the old pods, shipped the fix to beta and verified restartCount 0.
Last night, in my timezone, Quave ONE started emailing me about beta API containers restarting.
10:28 PM.
10:35 PM.
10:42 PM.
10:50 PM.
10:55 PM.
11:36 PM.
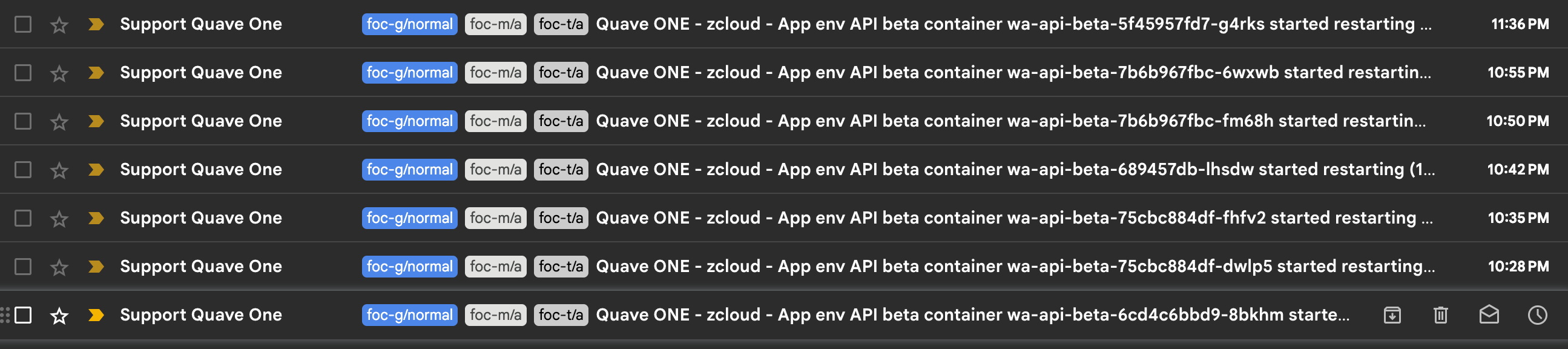
When I woke up and saw this list, my question was obvious:
see these restarts on my timezone, why are they happening? is it fixed?
The interesting part is that this question was not the beginning of the fix.
Before I woke up and sent that message, Codex had already worked through the issue. It investigated the failure, found the bad path, patched it, merged it to beta, waited for the deployment and ran the final QA.
My morning question was the audit.
Was the runtime signal real? Yes.
Was it still happening? No.
That is the part I want to show here: AI is much more powerful when the product can talk back to it, and when the AI can keep going until the platform proves the result.
Not a chatbot.
Not autocomplete.
Not "generate this function".
A full harness.
I wrote about this in The Visionary Steward. The point there was simple: code generation is not the hard part anymore. The hard part is foundation, skills and workflows. The hard part is giving AI the rules of the world, then connecting it to a real feedback loop.
This restart was a real example of that.
We were testing new automation APIs, provider keys and MCP key management in Quave ONE beta. Exactly the kind of product surface where you do not want AI to be sloppy.
What happened
Codex had the repo instructions, the product rules and Quave ONE MCP.
So instead of guessing, it could look at the real environment.
By the time I asked about the emails, the code fix had already been merged and deployed to beta. This was not "please start debugging". This was "prove whether the emails from last night still describe the current state".
It checked the beta API app environment, the current deployment, the current content version, pod health, logs, metrics, runs and the recent QA path.
Then it came back with this:
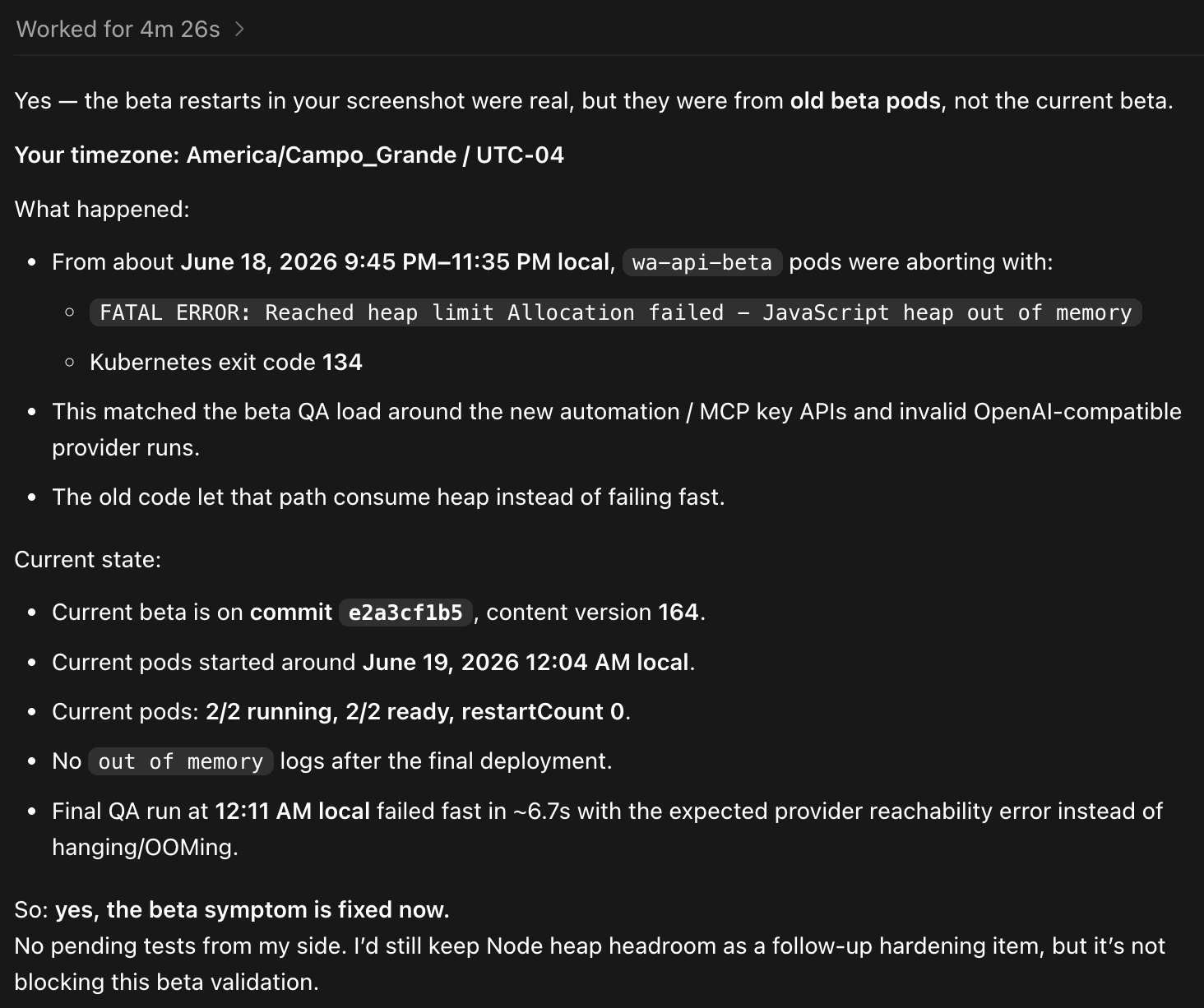
The short version:
- The restarts were real.
- They were from old beta pods, not the current beta pods.
- The failing pods were
wa-api-betapods. - They were aborting with
FATAL ERROR: Reached heap limit Allocation failed - JavaScript heap out of memory. - Kubernetes reported exit code
134. - The timing matched our beta QA around the new automation, MCP key and provider-key APIs.
- The old code allowed one invalid OpenAI-compatible provider path to consume heap instead of failing fast.
That last line is the bug.
An invalid provider configuration should not become a long-running path that eats memory. It should fail fast, explain the problem, save the run result and let the system continue.
The fix
The lazy answer would be: increase memory.
Sometimes that is right. Here it would only hide the real problem.
The right fix was a preflight step for OpenAI-compatible automation providers. Before the automation run enters the expensive agent generation path, the backend validates the configured provider and runs a cheap reachability check. If it is invalid, the run fails quickly with the expected provider reachability error.
No hanging.
No heap growth until the process dies.
No repeated beta pod restarts.
This also had to follow the product rules, not just patch the symptom:
- same validations as the UI
- backend validation shared by UI, API and MCP paths
- clear user-facing error
- persisted run result
- audit trail where actions happen
- MCP key management as its own permission
- MCP keys that can create or manage only keys with the same or fewer permissions
That is the difference between asking AI to write code and using AI to steward a product.
The verification
After the final deployment, beta was on commit e2a3cf1b5, content version 164.
The current pods had started around June 19, 2026, 12:04 AM local time.
The state was:
2/2pods running2/2pods readyrestartCount 0- no
out of memorylogs after the final deployment - final QA failed fast in about
6.7swith the expected provider reachability error
That last bullet is important.
A failed run can be correct. If the provider URL is invalid, the right behavior is not success. The right behavior is a quick, controlled, understandable failure.
So yes, the restarts in the screenshot were real.
And yes, that beta symptom was fixed.
Quave ONE as the whole picture
This is why I keep saying Quave ONE is not only hosting.
Hosting is one piece.
The bigger product is the operating surface around your apps: deploys, rollbacks, logs, metrics, restart notifications, alerts, automations, provider keys, MCP keys, permissions, audit history, run history and AI access through MCP.
When those pieces are connected, your AI assistant is not blind anymore.
It can ask the platform what happened. It can inspect the current state. It can compare old pods and new pods. It can connect a restart to a deploy. It can connect a deploy to a commit. It can rerun QA and check if the runtime signal disappeared.
That is very different from pasting logs into a chat window.
And it is very different from opening ten dashboards manually while half-asleep at midnight.
The steward is still required
I do not think this removes the human.
It changes the human job.
The human does not need to manually search every log line, but the human still needs to decide what matters.
In this case, the important judgments were:
- old pods vs current pods matters
- beta vs production matters
- OOMKilled vs Node heap abort matters
- fail-fast validation is better than adding memory
- a key that creates another key cannot grant more power than it has
That is stewardship.
AI did a lot of the work, but the work was valuable because it was inside a system with product rules, infrastructure access, deployment flow and runtime feedback.
The best workflow is not "AI writes code".
The best workflow is:
product signal
-> AI investigates with real context
-> human stewards the decision
-> AI changes the system
-> platform verifies the result
This is what happened here.
A restart email became an investigation, a fix, a beta deploy and a verified result.
In one loop.
That is the power of an AI harness.
And this is why we are building Quave ONE this way.
Connect your AI assistant to Quave ONE MCP, turn on restart notifications, and let your product talk back.
Then steward the result.